
Contextualizing Hate Speech Classifiers with Post Hoc Explanation
Summary
In analyzing hate speech datasets — including our own, the Gab Hate Corpus — we found a pattern that was then becoming known in the literature: classifiers of hate speech (or, similarly, categories of toxic language) tend to reflect the biases in training data. These biases are specific social, e.g., the tendency to label language concerning African Americans as hate speech, simply because the language in question mentions the phrase “African American” or “black.” We applied a recently developed interpretability approach for measuring these biases, called Sampling and Occlusion (SOC), which essentially approximates the effect of masking a given word or phrase on the predictions of a model on the entire sentence in question. After using SOC for measuring biases by computing the mean importance given to social group terms (e.g., “black,” “jewish,” or “gay”), we then developed a novel technique for mitigating bias in hate speech classifiers which was based on SOC.
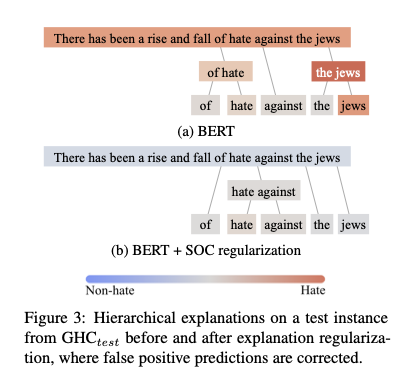
By adding a new component to the classification loss, which was the cumulative SOC importance given to social group terms across a given instance, we were able to significantly reduce models’ bias while simultaneously improving their performance on hate speech classification. By regularizing models in this way to focus more on the context versus simply using the social group term as a heuristic indicative of the presence of hate speech, we successfully applied a technique for model interpretation to the task of debiasing and improving models trained on imbalanced data.
Presentation
Slides which were presented at the Annual conference for the Association for Computational Linguistics (2020, remote):